x = application code, _ = time spent in the databaseSwedenCpp Stockholm0x06

for C++ developer
SQLite3
Developed ~2000 by D. Richard Hipp
(Dwayne Richard Hipp)Developed as kind of SQL database stub (my words)
Put into public domain
Took off
SQLite3
Developed ~2000 by D. Richard Hipp
(Dwayne Richard Hipp)Developed as kind of SQL database stub (my words)
Put into public domain
Took off
Any SQLite3 user here?
What is SQLite3
What is SQLite3
Not the small version of …
…MariaDB/MySQL, PostgreSQL, MSSQL, Oracle…
What is SQLite3
Not the small version of …
…MariaDB/MySQL, PostgreSQL, MSSQL, Oracle…
- each database
attach up to 125 databases
up to 2,147,483,646 tables
up to 2^64 rows in a tables
140 terabytes
What is SQLite3
Not the small version of [you name it]
What is SQLite3
Not the small version of [you name it]
Zero config relational database
Can be statically linked into your application
What is SQLite3
Zero config relational database
Can be statically linked into your application
Shipped as a single C header/source file
Super simple to add to your application
It just works, defaults already OK
Optimized/fine-tuned via compile time options
What is SQLite3
Not the small version of [you name it]
Zero config relational database
Can be statically linked into your application
What is SQLite3
Not the small version of [you name it]
Zero config relational database
Can be statically linked into your application
In process relational database
Relational application file format
What is SQLite3
In process relational database
Relational application file format
The app decides the thread model, 0..n
Multiple writers not the primary use case
(file locking)Relational data layout and key value storage
Support of transactions
Therefore often the better own file format
What is SQLite3
Not the small version of [you name it]
Zero config relational database
Can be statically linked into your application
In process relational database
Relational application file format
And much more …
What is SQLite3
And much more ..
- Various extensions
Json
Full text search
R-Tree tables
CSV tables from file
….
What is SQLite3
And much more …
- And even more
A great opens source project
Excellent tested (FAA DO-178 B or C)
Well documented
An in-memory data store
….
What is SQLite3
Not the small version of [you name it]
In process relational database
Zero config relational database
Relational application file format
Can be statically linked into your app
And much more … and even more …
Performance
Performance
Since I have it in the title ….
Performance
Since every presentation needs some charts ….
Performance
- Poor mans visualization legend
x = runtime of application code
_ = run time spent in the database
Performance, a simplified overview
Performance, a simplified overview
x = application code, _ = time spent in the databaseBase case: some ORM and/or library …
xxxxx_______________________________________________Performance, a simplified overview
x = application code, _ = time spent in the databaseBase case: some ORM and/or library …
xxxxx_______________________________________________Optimizing application code
xx________________________________________________Performance, a simplified overview
x = application code, _ = time spent in the databaseBase case: some ORM and/or library …
xxxxx_______________________________________________Optimizing application code
xx________________________________________________Understanding/using SQL + database normalization
xx_______________Performance, additional notes
If you care about performance …
... care about the things that matter.
Performance, additional notes
Care about the things that matter
Different type of performance
Time to market …
Daily migration of schema and data due to new customer requests, …
Run with whatever back-end wanted/needed, like bug tracer, wiki, shop software, …
Performance, additional notes
Care about the things that matter
If it is runtime, usually for C++ , embedded
SQL
database normalization
indexes
query plan execution
and of course somehow sane C++
Learn SQL, it’s simple, beautiful and fun
Learn SQL, it’s simple, beautiful and fun
Since C++11 SQL is a pleasure to write in C++ code
Learn SQL, it’s simple, beautiful and fun
Since C++11 SQL is a pleasure to write in C++ code
constexpr const char*
mySqlStatement()
{
R"~(
select/insert/update ...
... what ever ...
... where ever ...
;
)~"
}Thanks to raw string literals !
Learn SQL, it’s simple, beautiful and fun
It’s fun and has cool words
Learn SQL, it’s simple, beautiful and fun
It’s fun and has cool words
4th generation declarative language
Relational algebra
Tuple relational calculus
Aggregate functions
Scalar functions
Learn SQL, it’s simple, beautiful and fun
It’s all about data
Learn SQL, it’s simple, beautiful and fun
It’s all about data
DDD
Learn SQL, it’s simple, beautiful and fun
It’s all about data
Data definition language
Data manipulation language
Data control language (*)
* In sqlite just file permissions
Learn SQL, it’s simple, beautiful and fun
Data definition
- Entity relation crash course
Entity is a table, columns are attributes
Attributes might have constraintsThere might be relations between entities
1:1, 1 to many / many to 1, many to manyThe goal:
keep redundancy to zero in the storage
ensure data correctness on storage level
Learn SQL, it’s simple, beautiful and fun
Data definition
Create tables, typed attributes(*) and relations
CREATE TABLE artist(
id INTEGER PRIMARY KEY,
name TEXT
);
CREATE TABLE track(
id INTEGER,
name TEXT,
artist INTEGER ,
FOREIGN KEY(artist) REFERENCES artist(id)
);- Its about referential integrity
A track without artist is impossible to have.
Learn SQL, it’s simple, beautiful and fun
Data definition
A well defined storage is always in a well defined state
No headache, it just works
In relational databases we trust
Learn SQL, it’s simple, beautiful and fun
Data manipulation
- Just master the basics
INSERT, UPDATE, DELETE
SELECT, ORDERED BY, GROUPED BY
Aggregate functions (avg, count, sum, …)
Scalar functions (trim, length, …)
JOINS (relations)
Just another programming challenge
OMG … JOINS !
OMG … JOINS !
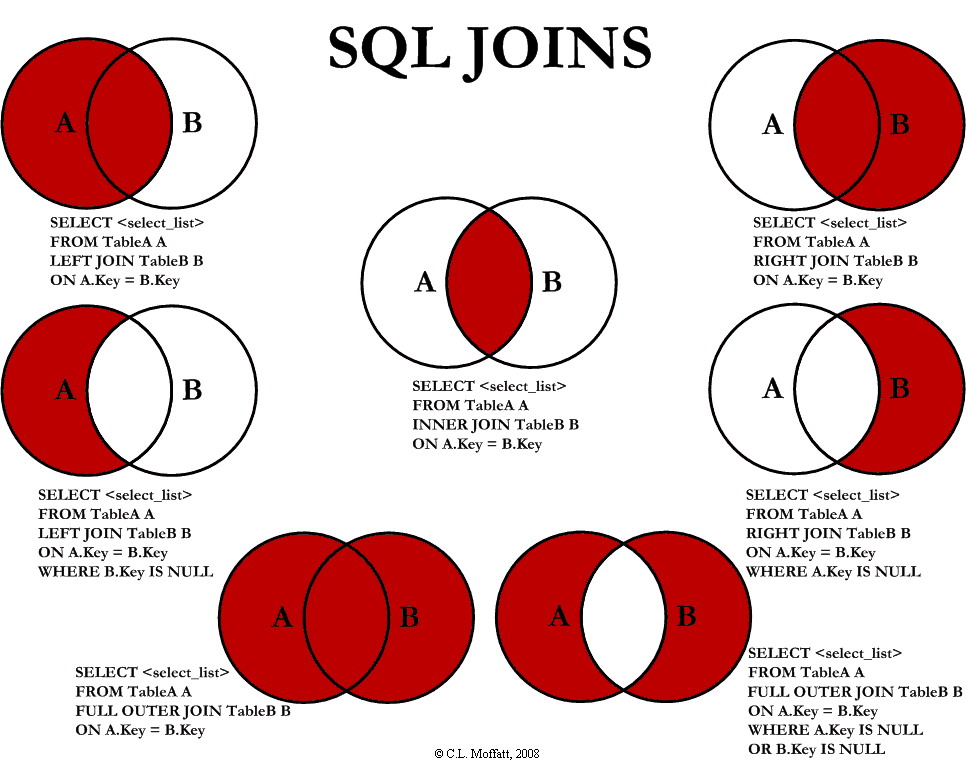
{kind=link}
Learn SQL, it’s simple, beautiful and fun
Structured Query Language
- The effect when you realize
An elegant SQL statement replaces boring spaghetti code and is much faster.
Data driven design/programming
Table driven design/programming
Ask the data storage questions …
Do list manipulation on the data storage …
Learn SQL, it’s simple, beautiful and fun
And even more fun with sqlite3
make own aggregate/scalar functions in C++
- And as extra bonus
event driven (trigger) …
on insert/update/delete ….
in process … Ideas? :-)
Learn SQL, it’s simple, beautiful and fun
The basics are simple
Basics can be learned in a hand full of hours
Not everyone needs to be an expert
Do not abstract SQL away (invent a own DSL)
Put data there where it should be
ERM has often more payoff than Class/Object diagram
Demo time
WITH RECURSIVE
xaxis(x) AS (VALUES(-2.0)
UNION ALL SELECT x+0.05 FROM xaxis WHERE x<1.2),
yaxis(y) AS (VALUES(-1.0)
UNION ALL SELECT y+0.1 FROM yaxis WHERE y<1.0),
m(iter, cx, cy, x, y) AS (
SELECT 0, x, y, 0.0, 0.0 FROM xaxis, yaxis
UNION ALL
SELECT iter+1, cx, cy, x*x-y*y + cx, 2.0*x*y + cy FROM m
WHERE (x*x + y*y) < 4.0 AND iter<28),
m2(iter, cx, cy) AS (
SELECT max(iter), cx, cy FROM m GROUP BY cx, cy),
a(t) AS (
SELECT group_concat( substr(' .+*#', 1+min(iter/7,4), 1), '')
FROM m2 GROUP BY cy)
SELECT group_concat(rtrim(t),x'0a') FROM a;Rush through some code
Might be a lite bit fast
- Main point is
not to memorize all details
to see how simple it is
- Therefore
lay back
fasten your seat belts
relax
Create the database connection
sqlite3* db = nullptr;
auto rc = sqlite3_open (name, &db);
if(rc != SQLITE_OK) {
std::cerr << "Unable to open database '" << name << "': "
<< sqlite3_errmsg (db);
sqlite3_close (db);
std::exit(EXIT_FAILURE);
}using the database and than, of course
// do not forgett to close !!!
sqlite3_close (db);Create the database connection
using database =
std::unique_ptr<sqlite3, decltype(&sqlite3_close)> ;database open_database(const char* name)
{
sqlite3* db = nullptr;
auto rc = sqlite3_open (name, &db);
if(rc != SQLITE_OK) {
std::cerr << "Unable to open database '" << name << "': "
<< sqlite3_errmsg (db);
sqlite3_close (db);
std::exit(EXIT_FAILURE);
}
return database{db, sqlite3_close} ;
}Create the database connection
From now on just use
auto db = open_database(":memory:");Excute arbitrary SQL statements
void execute (not_null<sqlite3*> db, const char* sql)
{
char* errmsg = 0;
int rc = sqlite3_exec (db.get (), sql, 0, 0, &errmsg);
if (rc != SQLITE_OK) {
std::cerr << "Unable to execute '" << sql << "': "
<< errmsg ;
sqlite3_free(errmsg) ;
std::exit(EXIT_FAILURE);
}
}
// Note: The not_null is from the MS GSL.Create initial data
constexpr const char* create_things()
{
return R"~(BEGIN TRANSACTION ;
CREATE TABLE things(id INTEGER PRIMARY KEY, name TEXT,value REAL);
INSERT INTO things VALUES(1,'one', 1.1);
INSERT INTO things VALUES(2,'two', 2.2);
COMMIT TRANSACTION ;
)~";
}
int main()
{
auto db = open_database(":memory:");
execute (db.get(), create_things());
// run your program....
}And now I have all - or no - things in memory.
Transaction
Transaction
JASG: Just another scope guard
Transaction
JASG: Just another scope guard
struct Transaction
{
Transaction(not_null<sqlite3*> db) : _db{db}{
execute(_db, "BEGIN TRANSACTION;") ;
}
~Transaction() {
if(_db) execute(_db, "ROLLBACK TRANSACTION;") ;
}
void commit() {
if(_db) execute(_db, "COMMIT TRANSACTION;") ;
_db = nullptr ;
}
Transaction (Transaction&&) = default ;
Transaction (Transaction&) = delete ;
Transaction& operator=(Transaction&) = delete ;
Transaction& operator=(Transaction&&) = delete ;
private:
sqlite3* _db ;
};Transaction
JASG: Just another scope guard
constexpr const char* create_things()
{
return R"~(
CREATE TABLE things(id INTEGER PRIMARY KEY, name TEXT,value REAL);
INSERT INTO things VALUES(1,'one', 1.1);
INSERT INTO things VALUES(2,'two', 2.2); )~";
}
int main()
{
auto db = open_database(":memory:");{
Transaction transaction{db};
execute (db.get(), create_things());
transaction.commit();
}
// now there is some data
}Compile reusable SQL
Compile reusable SQL
each SQL command needs to be compiled, expensive
compiled SQL commands can have parameters
Compile reusable SQL
each SQL command needs to be compiled, expensive
compiled SQL commands can have parameters
-- sqlite syntax
INSERT INTO things VALUES(?,?,?); -- index 1, 2 , 3
-- or with names
INSERT INTO things VALUES(@id,@name,@value);
-- indexes still workCreate the compiled statement
sqlite3_stmt* stmt = nullptr;
int rc = sqlite3_prepare_v2 (db,
sql.c_str (), sql.length(),
&stmt, nullptr);
if (rc != SQLITE_OK) {
std::cerr << "Unable to create statement '" << sql << "': "
<< sqlite3_errmsg(db.get ());
std::exit(EXIT_FAILURE);
}use stmt
don’t forget
sqlite3_finalize(stmt) ;Compile some SQL
using statement =
std::unique_ptr<sqlite3_stmt, decltype(&sqlite3_finalize)> ;statement create_statement(not_null<sqlite3*> db,
const std::string& sql)
{
sqlite3_stmt* stmt = nullptr;
int rc = sqlite3_prepare_v2 (db,
sql.c_str (), sql.length(),
&stmt, nullptr);
if (rc != SQLITE_OK) {
std::cerr << "Unable to create statement '" << sql << "': "
<< sqlite3_errmsg(db.get ());
std::exit(EXIT_FAILURE);
}
return statement(stmt, sqlite3_finalize);
}Compile some SQL
From now on just use
auto stmt = create_statement(db.get(),
"INSERT INTO things VALUES(@id,@name,@value);");Setting statement parameter’s
Setting statement parameter’s
Extra lightning talks on how to do this exists …
Setting statement parameter’s
Extra lightning talks on how to do this exists …
The point here is just to show sqlite3_bind_TYPE
→ rc sqlite3_bind_TYPE (stmt, index, TYPE_value)
Setting statement parameter’s
void parameter(not_null<sqlite3_stmt*> stmt,
int index, int64_t value){
if (sqlite3_bind_int64 (stmt, index, value) != SQLITE_OK){
throw "TODO" ;
}
}
// void parameter( ... double value) sqlite3_bind_real
void parameter(not_null<sqlite3_stmt*> stmt,
int index, const std::string& value) {
if(sqlite3_bind_text (stmt.get(), index,
value.c_str (), value.size (),
SQLITE_TRANSIENT) != SQLITE_OK){
throw "TODO" ;
}
}
// void parameter( ... blob& value) sqlite3_bind_blob
// for temporary, SQLITE_TRANSIENT, sqlite get a copySetting statement parameter’s
→ rc sqlite3_bind_TYPE (stmt, index, TYPE_value)
int/int64/double
null , no value
text/text16/text64
blob/blob16/blob64
Text and blob, SQLITE_TRANSIENT vs SQLITE_STATIC
Looping through a query result
Looping through a query result
sqlite3_step(stmt) executes a statement.
- Returns one of
There was an error
OK for INSERT/UPDATE/…
A row of data for you
Done, no more data
Looping through a query result
One way to dot it:
Give me a callback
If there is data, call the callback
If the callback says continue, step next
→ No need to write loops as user.
The callback can be a lambda, a function, function object, …
Looping through a query result
using stmt_callback = //callback to handle current row
std::function<bool(not_null<sqlite3_stmt*>)> ;Looping through a query result
void run(not_null<sqlite3_stmt*> stmt,
stmt_callback callback = stmt_callback{})
{
using reset_guard // JASG: Just another scope guard
= std::unique_ptr<sqlite3_stmt, decltype (&sqlite3_reset)>;
auto reset = reset_guard (stmt.get(), &sqlite3_reset);
auto next_step = [&](int rc){
if (rc == SQLITE_OK || rc == SQLITE_DONE)
return false ;
else if (rc == SQLITE_ROW)
if(callback) return callback(stmt);
// else ... some error handling
return false ;
};
while(next_step(sqlite3_step(stmt))) ;
}Handling a row
A callback example
bool dump_current_row(not_null<sqlite3_stmt*> stmt)
{
for (int i = 0 ; i < sqlite3_column_count(stmt); ++i) {
// get the current field value and print it
std::cout << "|" ;
}
std::cout << "\n" ;
return true ;
}Get the current field value
auto columntype = sqlite3_column_type(stmt, i) ;
if(columntype == SQLITE_NULL) {
std::cout << "<NULL>" ;
}
else if (columntype == SQLITE_INTEGER){
std::cout << sqlite3_column_int64(stmt, i);
}
else if (columntype == SQLITE_FLOAT){
std::cout << sqlite3_column_double(stmt, i) ;
}
else if (columntype == SQLITE_TEXT ){
auto first = sqlite3_column_text (stmt, i);
std::size_t s = sqlite3_column_bytes (stmt, i);
std::cout << "'" << (s > 0 ?
std::string((const char*)first, s) : "") << "'";
}
else if (columntype == SQLITE_BLOB ){
std::cout << "<BLO000B>" ;
}Get the current field value
sqlite3_column_count
sqlite3_column_type
sqlite3_column_bytes(16)
sqlite3_column_int(64)
sqlite3_column_double
sqlite3_column_text(16)
sqlite3_column_blob
And that’s it, the basic
And that’s it, the basic
sqlite3_open
sqlite3_execute
sqlite3_prepare_v2
sqlite3_step + return value
sqlite3_bind_TYPE .. app → sqlite
sqlite3_column_TYPE + helpers .. app ← sqlite
Using the code
constexpr const char* create_things()
{
return R"~(
CREATE TABLE things(id INTEGER PRIMARY KEY, name TEXT,value REAL);
INSERT INTO things VALUES(1,'one', 1.1);
INSERT INTO things VALUES(2,'two', 2.2); )~";
}
int main()
{
auto db = open_database(":memory:");{
Transaction transaction{db};
execute (db.get(), create_things());
transaction.commit();
}
auto stmt = create_statement(db.get(), "SELECT * FROM things;");
run(stmt.get(), dump_current_row);
}
//
// 1|'one'|1.1|
// 2|'two'|2.2|Exercise
Column handling in the callback
Exercise
Column handling in the callback
auto on_row = [](not_null<sqlite3_stmt*> stmt)
{
for (int i = 0 ; i < sqlite3_column_count(stmt.get()); ++i) {
// get the current field value .
}
return true ;
}Exercise
Column handling in the callback
auto on_row = [](not_null<sqlite3_stmt*> stmt)
{
for (int i = 0 ; i < sqlite3_column_count(stmt.get()); ++i) {
// get the current field value ..
}
return true ;
}- should possible be
for (auto column : columns(stmt)) …
Exercise
Column handling in the callback
auto on_row = [](not_null<sqlite3_stmt*> stmt)
{
for (int i = 0 ; i < sqlite3_column_count(stmt.get()); ++i) {
// get the current field value ...
}
return true ;
}- should possible be
for (auto column : columns(stmt)) …
But, what is column ?
Security, lets look at this
Something happens
Create initial data, return the insert statement
statement create_things2(not_null<sqlite3*> db) {
Transaction transaction(db) ;
execute(db, R"~(CREATE TABLE things
(id INTEGER PRIMARY KEY, name TEXT,value REAL); )~");
auto insert_thing = create_statement(db,
"INSERT INTO things VALUES(@id,@name,@value);");
// create the additive identity thing
parameter(insert_thing.get(), 1, int64_t{0}) ;
parameter(insert_thing.get(), 2, "") ;
parameter(insert_thing.get(), 3, double{0.0}) ;
run (insert_thing.get()) ;
transaction.commit() ;
// return creator
return insert_thing ;
}Something bad happens
void somehwere()
{
auto db = open_database(":memory:");
auto add_thing = create_things2(db.get());
// add a second thing
parameter(add_thing.get(), 1, int64_t{1}) ;
parameter(add_thing.get(), 2, "first") ;
parameter(add_thing.get(), 3, "second") ; // Mistake !!
run(add_thing.get());
}But we just wanted to help and deduce the type for setting a parameter …
Someone else deals with things
I know what a thing is, it is int/text/double!
Printing is easy!
bool print_thing(not_null<sqlite3_stmt*> stmt) {
// get the int64
auto id = [&](){return sqlite3_column_int64(stmt, 0);} ;
//get the text
auto name = [&](){ auto first = sqlite3_column_text (stmt, 1);
std::size_t s = sqlite3_column_bytes (stmt, 1);
return s > 0 ? std::string ((const char*)first, s)
: std::string{};
};
// get the double
auto value = [&]() {return sqlite3_column_double(stmt, 2);};
// and process the data
std::cout << id() << ", " << name() << ", " << value() << std::endl;
return true ;
}Something bad has happened
// parameter(insert_thing.get(), 1, int64_t{0}) ;
// parameter(insert_thing.get(), 2, "") ;
// parameter(insert_thing.get(), 3, double{0.0}) ;
// parameter(add_thing.get(), 1, int64_t{1}) ;
// parameter(add_thing.get(), 2, "first") ;
// parameter(add_thing.get(), 3, "second") ; // Mistake !!
auto stmt = create_statement(db.get(), "SELECT * FROM things;");
run(stmt.get(), dump_current_row);
run (stmt.get(), print_thing);Something bad has happened
Generic print row gets it right, it cares about types
0|''|0|
1|'first'|'second'| # dump_current_row know the typeSomething bad has happened
print_thing, where we have been sure what to expect
0, , 0
1, first, 0 # this might become expensiveWe work with wrong data, and no one told us!
Something bad has happened
print_thing, where we have been sure what to expect
0, , 0
1, first, 0 # this might become expensiveIf you do not care about your types,
someone else will do it for you.
... but maybe not in the way you want!
Care about the types
auto on_row = [](not_null<sqlite3_stmt*> stmt)
{
for (int i = 0 ; i < sqlite3_column_count(stmt.get()); ++i) {
// get the current field value ...
}
return true ;
}- should possible be
for (auto column : columns(stmt)) …
When we know what column is
We can provide a secure, convenient interface
#include <iostream>
#include <sl3/database.hpp>
int main()
{
using namespace sl3;
Database db(":memory:");
db.execute("CREATE TABLE tbl(f1 INTEGER, f2 TEXT, f3 REAL);");
// insert with type insurance
auto cmd = db.prepare("INSERT INTO tbl(f1, f2, f3) VALUES(?,?,?);",
DbValues ({Type::Int,Type::Text, Type::Real})) ;
//this will work,
cmd.execute({ {1}, {"one"}, {1.1} } );
try{
// this will throw since "2" is a wrong type
cmd.execute({ {"2"}, {"two"}, {2.1} } );
} catch (const Error& e) {
std::cout << e << std::endl;
}
}Or, if we decide to support duck typing
Provide a secure (*), convenient interface
// ommit types in prepare, do what evet
//db.prepare("INSERT INTO tbl(f1, f2, f3) VALUES(?,?,?);") ;
for(auto& row :db.select("SELECT * FROM tbl;"); {
for (auto& field : row) {
std::cout << typeName (field.getType()) << "/"
<< typeName (field.getStorageType())
<< ": " << field << ", ";
}
std::cout << std::endl;
}Variant/Int: 1, Variant/Text: one, Variant/Real: 1.1,
Variant/Text: 2, Variant/Text: two, Variant/Real: 2.1,* no undefined behaviour/value
request the wrong value type will throw
Protect against invalid reads
and have a secure, convenient interface
try {
// SELECT will throw if any types is not as wanted
Dataset ds = db.select ("SELECT * FROM tbl;",
{ Type::Int, Type::Text, Type::Real });
for(auto& row : ds) {
// here I can trust the type, (could be NULL :-)
row.at(0).getInt();
row.at(1).getText();
row.at(2).getReal();
}
}
catch (const Error& e)
{
std::cout << e << std::endl ;
}Example implementation
100% C++ wrapper
no direct include of sqlite header
change MB of include again some linesaccess to all sqlite features possible
all sqlite data structures accessable, nothing is hiddenusable, but use primarily as inspiration
It’s under ongoing work, C++98/11/14/17 …
interface might change (if no one ask me to not do it)
Thanks for listening!
Thanks for listening!
If parts of this presentation looked interesting but have been handled to short/fast…
Thanks for listening!
If parts of this presentation looked interesting but have been handled to short/fast…
Request an in depth tutorial or workshop
→ ask you local C++ community!
Thanks for listening!
If parts of this presentation looked interesting but have been handled to short/fast…
Request an in depth tutorial or workshop
→ ask you local C++ community!
- Visit
www.swedencpp.se :-)